

[2025/06/09]
2025년부터 RAG에 관한 글만 올리는 이유는 Data-logger나 IoT장비의 최종에서는 인간이 판단하거나, 인간이 설정해 놓은 기능이 수행되게 됩니다.
대표적으로 NodeRED, Home-Assistan와 같은 툴을 사용합니다.
이런 툴의 한계는 요구자의 요구에 맞추어진 조회 시스템을 통해서만 상황을 파악할 수 있다는 것입니다.
다양한 질문에 답하기 위해서는 AI를 이용할 수 밖에 없습니다.
RAG는 보고서(Text, Image가 포함된)로 작성된 문서를 기반으로 질문에 답변을 하기에 적합합니다.
물론 보고서를 추출하는 프로그램으로 질적 차이가 발생되지만, 상관분석이 가능하다는 것이 좋은 예입니다.
RAG를 전통적인 RAG와 Agent를 사용하는 RAG로 구분하여 설명하고자 합니다.
동작 방식
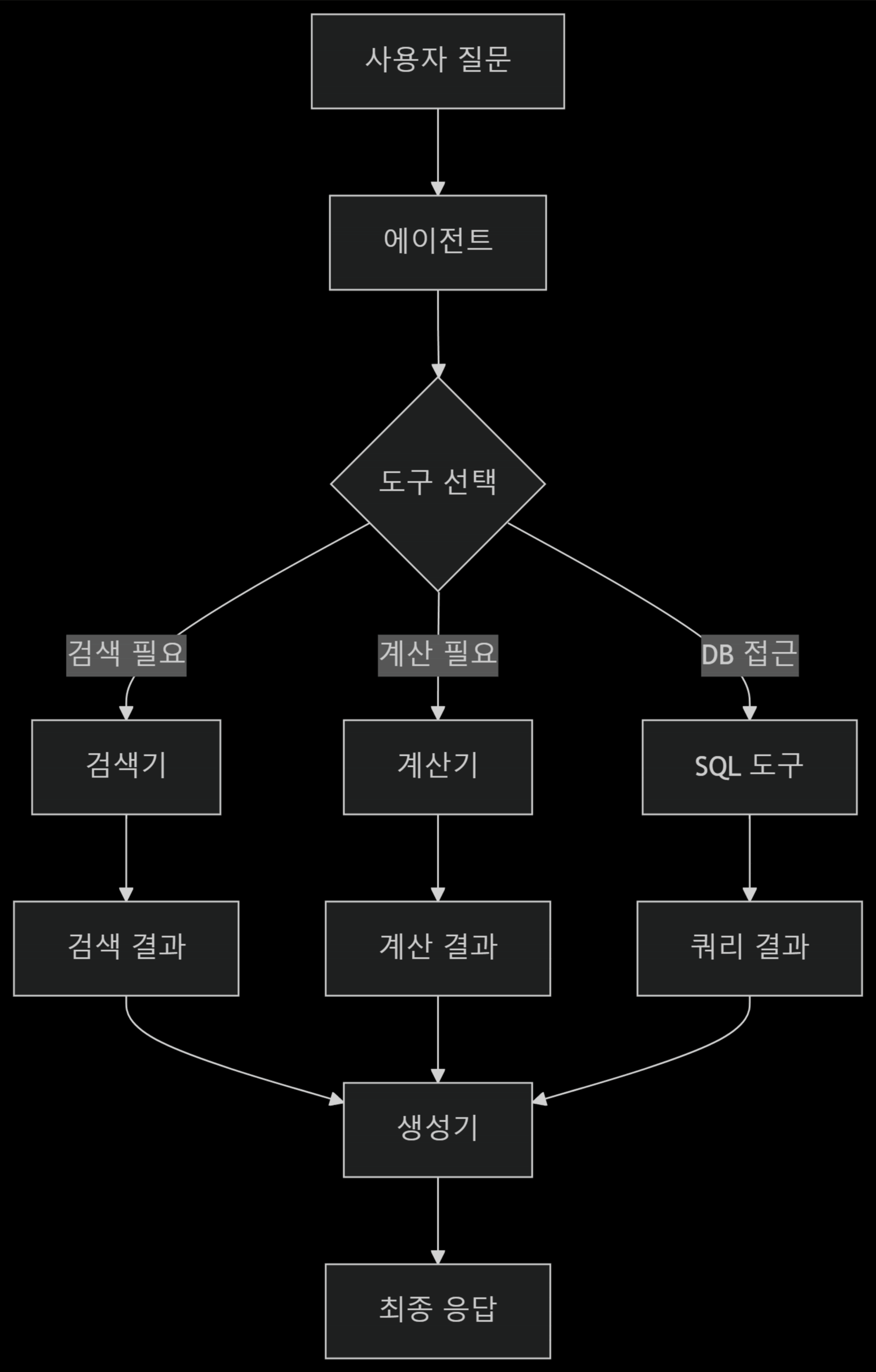
Traditional RAG(Non-Agent RAG)
특징:

- 선형적인 흐름: 검색과 생성이 비교적 순차적으로 이루어집니다.
- 제한된 추론 및 계획: 검색된 문서가 충분하지 않거나 질의가 복잡하여 여러 단계의 추론이 필요한 경우, 시스템 스스로 추가적인 행동을 계획하거나 실행하기 어렵습니다.
- 고정된 검색 전략: 일반적으로 질의 임베딩과 문서 임베딩 간의 유사도에 기반한 단일 검색 전략을 사용합니다.
- LLM의 역할: LLM은 주로 최종 답변을 생성하는 데 사용되며, 검색 프로세스 자체에 대한 통제권은 적습니다.
- 오류 처리의 한계: 검색된 정보가 부족하거나 부정확할 경우, 이를 스스로 감지하고 보완하기 어렵습니다.
장점:
- 구현의 단순성: 에이전트 기반 시스템에 비해 구조가 간단하고 구현하기 쉽습니다.
- 빠른 응답 시간: 복잡한 추론 과정이 없으므로 비교적 빠르게 답변을 생성할 수 있습니다.
- 자원 효율성: 추가적인 반복이나 도구 사용이 없으므로 컴퓨팅 자원 소모가 적을 수 있습니다.
단점:
- 오류 복구의 어려움: 잘못된 정보가 검색되었을 때 스스로 오류를 수정하거나 다른 정보원을 탐색하기 어렵습니다.
- 복잡한 질의 처리의 한계: 다단계 추론, 외부 도구 사용, 동적인 정보 탐색이 필요한 복잡한 질의에는 취약합니다.
- “정보 부족” 문제: 검색된 정보가 불충분할 경우, 부정확하거나 불완전한 답변을 생성할 수 있습니다.
Agent RAG
특징:
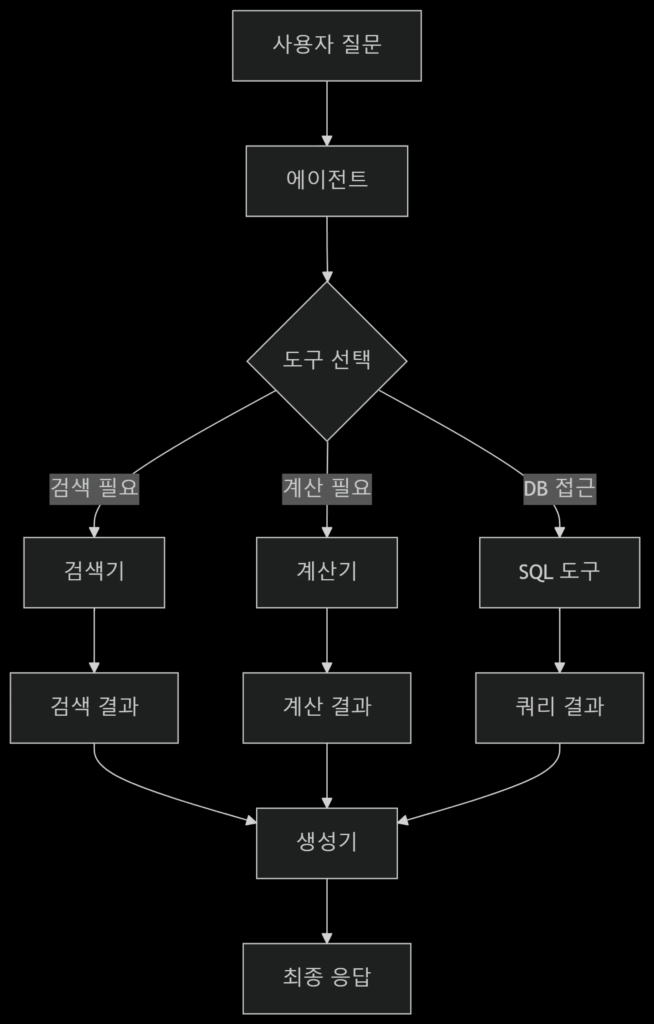
- 동적인 추론 및 계획: Agent는 질의의 복잡성에 따라 동적으로 계획을 수립하고, 다단계 추론을 통해 문제를 해결합니다.
- 다양한 도구 사용: 검색 외에 웹 검색, 계산, 외부 API 호출 등 다양한 도구를 활용하여 정보 수집 및 처리가 가능합니다.
- 반복적인 실행: 필요한 경우 정보를 얻기 위해 여러 번의 검색이나 도구 사용을 반복할 수 있습니다 (e.g., ReAct, Self-Refine 패턴).
- 오류 처리 및 복구: 잘못된 정보를 얻거나 계획이 실패했을 경우, 이를 인지하고 다른 방법을 시도하거나 재시도할 수 있습니다.
- LLM의 역할: LLM은 단순한 생성기가 아니라, 문제 해결의 “컨트롤러”이자 “추론 엔진”의 역할을 수행합니다.
장점:
- 복잡한 질의 처리 능력 향상: 다단계 추론, 외부 정보 탐색, 계산 등이 필요한 복잡한 질의에 효과적으로 대응할 수 있습니다.
- 정보의 정확성 및 풍부함 증가: 필요한 정보를 얻기 위해 다양한 수단과 반복적인 과정을 거치므로, 더욱 정확하고 풍부한 답변을 생성할 수 있습니다.
- “한계” 돌파: LLM의 지식 한계나 검색 결과의 한계를 외부 도구와 상호작용하여 극복할 수 있습니다.
- 유연성: 다양한 시나리오와 질의 유형에 더욱 유연하게 대응할 수 있습니다.
단점:
- 예측 불가능성: Agent의 행동이 복잡해질수록 예측하기 어려워지거나 원치 않는 결과가 나올 가능성이 있습니다.
- 구현의 복잡성: 도구 통합, 프롬프트 엔지니어링, 에이전트의 계획 및 실행 로직 설계 등 구현이 훨씬 복잡합니다.
- 응답 시간 증가: 다단계 추론, 반복적인 도구 사용으로 인해 응답 시간이 길어질 수 있습니다.
- 추가적인 비용: LLM 호출 횟수가 증가하고, 외부 API 사용에 따른 비용이 발생할 수 있습니다.
요약 및 비교
| 특징 | Agentic RAG | Traditional RAG |
|---|---|---|
| 목표 | 복잡한 문제 해결을 위해 능동적으로 정보를 탐색하고 도구를 활용 | 검색된 문서 기반으로 질문에 직접 답변 생성 |
| 워크플로우 | 동적/반복적 (질의 -> 계획 -> 도구 사용 -> (피드백/반복) -> 생성) | 선형적 (질의 -> 검색 -> 생성) |
| LLM의 역할 | 컨트롤러, 추론 엔진, 계획 수립자 | 주로 생성기 (Generative model) |
| 도구 사용 | 검색 도구 외 다양한 외부 및 내부 도구 (웹 검색, 계산기 등) | 주로 단일 검색 도구 (Retrieval tool) |
| 추론 능력 | 다단계 추론, 동적 계획 수립 및 실행 | 제한적, 주어진 컨텍스트 내에서 추론 |
| 복잡성 | 복잡 | 단순 |
| 응답 시간 | 느려질 수 있음 | 빠름 |
| 활용 분야 | 복잡한 의사결정 지원, 데이터 분석, 복합적인 작업 자동화, 고급 챗봇 | 간단한 질의 응답, FAQ 챗봇, 정보 요약 등 |
성능 고려사항
| 특징 | Agentic RAG | Traditional RAG |
|---|---|---|
| 지연 시간 | 높음 (1-5s) | 낮음 (100-500ms) |
| 비용 | 높음 (LLM 호출 횟수 증가) | 낮음 |
| 정확도 | 복잡한 질문에서 월등히 높음 | 단순 질문에서 높음 |
| 확장성 | 우수 (모듈식 도구 추가) | 제한적 |
| 디버깅 용이성 | 복잡함 | 쉬움 |
Agent RAG가 설명이 적인 것은, 1) Local에서 운영하기 힘들고, 2) 예측할 수 없는 답변, 3) 평가 기준이 애매하다는 것이 있습니다.
Agent RAG Example
from langchain.agents import AgentExecutor, create_tool_calling_agent
from langchain_community.tools import Tool
# 도구 정의
tools = [
Tool(
name="KeywordSearch",
func=retriever.get_relevant_documents,
description="키워드 기반 문서 검색"
),
Tool(
name="SemanticSearch",
func=vectorstore.similarity_search,
description="의미 기반 문서 검색"
),
Tool(
name="SQLQuery",
func=sql_tool.run,
description="데이터베이스 쿼리 실행"
)
]
# 에이전트 생성
agent = create_tool_calling_agent(llm, tools, prompt_template)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# 동적 RAG 실행
def agent_rag(question):
response = agent_executor.invoke({
"input": question,
"chat_history": [] # 필요시 대화 기록 활용
})
return response["output"]
Traditional RAG Example
from langchain.retrievers import BM25Retriever
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
# 초기화
retriever = BM25Retriever.from_texts(docs)
vectorstore = FAISS.from_texts(docs, OpenAIEmbeddings())
llm = ChatOpenAI(model="gpt-4")
# 고정 파이프라인
def simple_rag(question):
# 검색 단계
keyword_results = retriever.get_relevant_documents(question)
semantic_results = vectorstore.similarity_search(question)
# 생성 단계
context = "\n".join([doc.page_content for doc in keyword_results + semantic_results])
response = llm.invoke(f"Context: {context}\n\nQuestion: {question}")
return response.content[ 2025/06/29 추가 ]
Agent를 이용하여, 부족한 용어 정의를 추가한 예
(관련자료: RAG GUI)
윤 영 기(尹泳祺)
YOON, Young-Ki
younggiyoon@hotmail.com
newton@eqboard.com